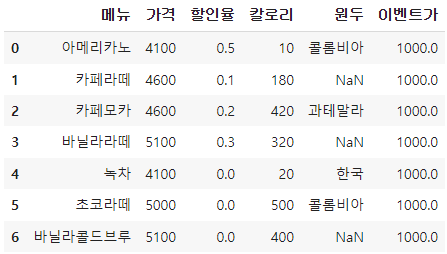
1. 라이브러리 불러오기
import pandas as pd
import numpy as np
2. csv 파일 불러와서 df라는 변수로 저장하기
df=pd.read_csv('cafe_menu.csv')
*csv = comma seperated values
3. 시리즈 만들기
menu=pd.Series(['아아','아라','바라'])
price=pd.Series([1000,2000,3000])
4. 데이터 프레임 만들기
menu=pd.DataFrame({
"menu": menu,
"price": price
})
menu=pd.DataFrame({
"menu": ['아아','아라','바라'],
"price": [1000,2000,3000]
})
5. 데이터 탐색 (EDA, Explorary Data Analysis)
1) 데이터 프레임 크기 (행, 컬럼)
df.shape
2) 데이터 샘플 보기 (default는 5개)
df.head()
df.tail()
df.head(7)
3) 기초통계량
df.describe()
df.describe(include="O")
4) 상관계수
df.corr(numeric_only_True)
5) 항목의 종류 수
df.nunique()
6) 항목별 개수
df['car']. nunique()
7) 항목별 개수 (size)
df['car'].value_counts()
8) 시리즈 타입 확인
type(df['가격'])
9) 데이터 프레임 타입 확인
type(df)
10) 컬럼의 전체적인 타입과 형태
df.info()
6. 특정 시리즈 또는 데이터 프레임 선택 조회
1) 시리즈 선택
df['메뉴']
2) 데이터 프레임 선택
df[['가격','메뉴']]
7. 데이터 인덱싱(행) / 슬라이싱(컬럼)
* 인덱싱 : 행 기준
* 슬라이싱: 컬럼 기준
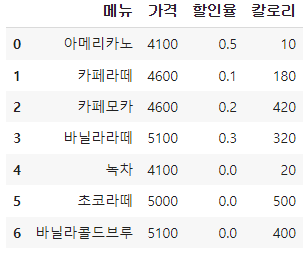
[loc 사용]
df.loc(인덱스 범위, 컬럼 명)
1) 인덱싱 (행)
df.loc[0] - 인덱스 0인 아메리카노 행 조회
df.loc[1:3] - 인덱스 1부터 3까지(아메리카노~바닐라라떼까지)의 행 조회
2) 슬라이싱 (컬럼)
df.loc[:, '가격'] - 가격 컬럼 조회
3) 특정 셀 조회 (인덱싱 & 슬라이싱)
df.loc[1, '가격'] - 인덱스 1인 카페라떼의 가격 조회
df.loc[2,'메뉴' : '가격']
df.loc[2,['메뉴','칼로리']]
df.loc[[1,2],['메뉴','가격']]
[iloc 사용]
df.iloc(인덱스 범위, 컬럼 범위)
1) 인덱싱 (행)
df.iloc[0]
df.iloc[1:3]
2) 슬라이싱 (컬럼)
df.iloc[:, 1]
3) 특정 셀 조회 (인덱싱 & 슬라이싱)
df.iloc[2, 0:2]
7. 자료형 변환
df['할인율']=df['할인율'].astype('float')
8. 데이터 추가 (새로운 행/열 추가)
1) 새로운 열 추가
df.loc[0, '원두'] = '콜롬비아'
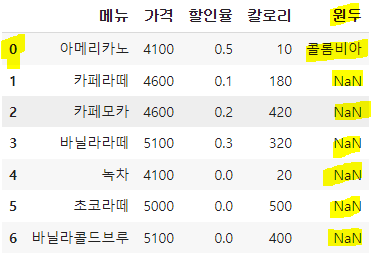
2) 리스트 형태로 행 추가
* 모든 요소가 다 채워져 있어야 함
df.loc['시즌']=['',6000,0,500,'한국']
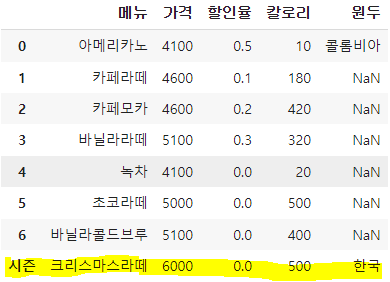
3) 딕셔너리 형태로 행 추가
* 모든 요소가 다 채워져 있지 않아도 됨
df.loc[7]={"메뉴":"에스프레소","가격":1000}
9. 새로운 컬럼 추가
(방법1) 새로운 컬럼을 0으로 채우기
df['비고']=0
(방법2) 새로운 컬럼을 NaN으로 채우기
import numpy as np
df['비고']=np.nan
(방법3) 존재하는 컬럼을 활용해 새로운 컬럼 만들기
df['할인가'] = df['가격'] * (1 - df['할인율'])
9. 데이터 삭제
1) 컬럼 삭제
df=df.drop('칼로리', axis=1)
2) 행 삭제
df=df.drop('칼로리', axis=0)
10. 데이터 소팅
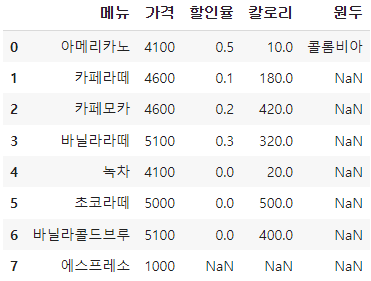
1) 인덱스 오름차순/내림차순 정렬
df=df.sort_index(ascending=False)
2) 값 기준 오름차순/내림차순 정렬
df = df.sort_values('가격', ascending=False)
df = df.sort_values(['가격','메뉴'],ascending=[False, True])
3) 데이터 소팅 후 인덱스 새로 만들기
df.reset_index(drop=True)
* drop=True는 기존 인덱스 없애는 것
11. 조건 필터링
1) 1개 조건
cond=df['할인율']>2
df[cond]
2) 2개 조건 (AND)
cond1= df['할인율'] >= 0.2
cond2= df['칼로리'] <400
df[cond1 & cond2]
3) 2개 조건 (OR)
cond1= df['원두']==콜롬비아
cond2= df['가격']<4500
df[cond1 || cond2]
12. 결측치 확인
1) 컬럼 결측치 요약
df.isnull().sum()

2) 컬럼별 결측치 확인
df.isnull()
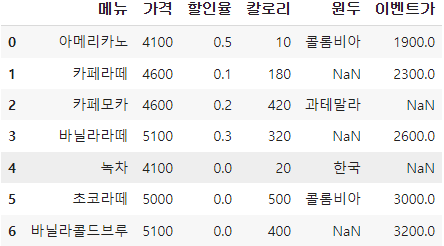
13. 결측치 채우기
df['이벤트가']=df['이벤트가'].fillna(1900)
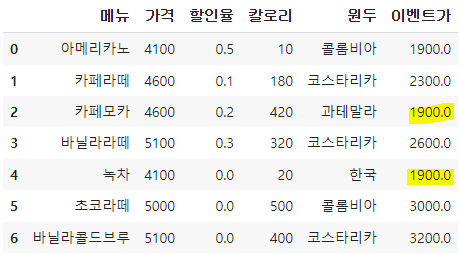
14. 값 변경
(방법1)
아메리카노 → 룽고, 녹차 → 그린티
df=df.replace('아메리카노', '룽고')
df=df.replace('아메리카노', '룽고').replace('녹차','그린티')
df=df.replace(1900,1500)
(방법2)
d={'아메리카노':'룽고', '녹차':'그린티'}
df=df.replace(d)
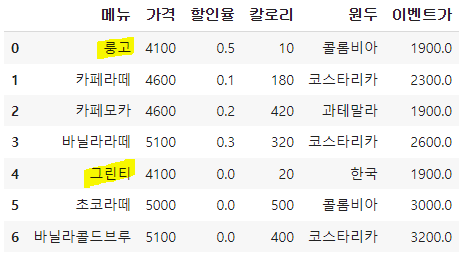
(방법3)
df.loc[3,'원두'] = '과테말라'
(방법4)
df.loc[:, '이벤트가'] = 1000